论文主题
同一用户在不同网站的密码相似度模型。
摘要
英文
Attackers increasingly use passwords leaked from one website to compromise associated accounts on other websites. Such targeted attacks work because users reuse, or pick similar, passwords for different websites. We recast one of the core technical challenges underlying targeted attacks as the task of modeling similarity of human-chosen passwords. We show how to learn good password similarity models using a compilation of 1.4 billion leaked email, password pairs. Using our trained models of password similarity, we exhibit the most damaging targeted attack to date. Simulations indicate that our attack compromises more than 16% of user accounts in less than a thousand guesses, should one of their other passwords be known to the attacker and despite the use of state-of-the art countermeasures. We show via a case study involving a large university authentication service that the attacks are also effective in practice. We go on to propose the first-ever defense against such targeted attacks, by way of personalized password strength meters (PPSMs). These are password strength meters that can warn users when they are picking passwords that are vulnerable to attacks, including targeted ones that take advantage of the user’s previously compromised passwords. We design and build a PPSM that can be compressed to less than 3 MB, making it easy to deploy in order to accurately estimate the strength of a password against all known guessing attacks.
中文
攻击者越来越多地使用从一个网站泄漏的密码来破坏其他网站上的关联帐户。之所以能够进行这种有针对性的攻击,是因为用户在不同的网站上重复使用或选择了相似的密码。我们重塑了针对目标攻击的核心技术挑战之一,即对人为选择的密码的相似性进行建模的任务。我们展示了如何使用14亿封泄漏的电子邮件和密码对来学习良好的密码相似性模型。使用我们训练有素的密码相似性模型,我们展示了迄今为止最具破坏性的针对性攻击。模拟表明,即使使用了最新的对策,只要攻击者知道他们的其他密码之一,我们的攻击就会在不到一千个猜测中破坏超过16%的用户帐户。我们通过涉及大型大学认证服务的案例研究表明,这种攻击在实践中也是有效的。我们将继续通过个性化密码强度计(PPSM)提出针对这种定向攻击的首次防御。这些是密码强度计,可以在用户选择容易受到攻击的密码时向用户发出警告,包括利用用户先前被盗用的密码的有针对性的密码。我们设计并构建了一个PPSM,可以将其压缩到小于3 MB,使其易于部署,以便针对所有已知的猜测攻击准确估计密码的强度。
关键字
明文密码;密码强度;深度学习
解决问题
由于用户在不同网站之间的密码复用或者密码相似度高的问题,攻击者进行“撞库”攻击有了可乘之机。攻击者可以使用同一个用户泄露的用户名和对应的密码进行撞库攻击。作为应对,NIST推荐企业对泄露密码数据库进行监控,如果发现用户在被泄露的的密码列表中,则强制其更改用户名和密码。
但是较多用户也会在不同网站之间使用相似的密码,快速判断数据库中是否存在相似密码是一个很大的问题。
方法
在这项工作中,我们将从了解人为选择的密码之间的相似性的角度研究凭证调整攻击。 我们探索使用现代机器学习技术对相似性进行建模的数据驱动方法。
这样就产生了一种新的有针对性的密码猜测攻击,其性能优于以前的所有攻击,以及一种新型的密码强度计的设计,该强度计在强度估算中包括了针对目标攻击的脆弱性。
本文解决的问题就是利用用户已经泄露的登录密码来猜测用户可能使用的其它密码,并使用机器学习的方法来构建了一个密码猜测模型,最后对这种攻击模型提出一种新的防御方案:vec-ppsm。
为了记忆方便,用户在不同网站之间重用密码(或者使用密码的一个简单的变体)的现象比较严重,或者在同一个网站上,更新密码的时候也很有可能是使用旧密码的一个简单的变体,因此,作者利用这个特点来设计一个密码猜测模型,攻击用户的密码,具体流程如图 1 所示:
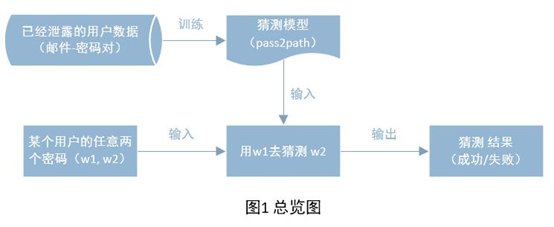
从图中可以看出,首先需要对数据进行建模,也就是利用机器学习的方法来训练出一个模型,这个模型叫做 pass2path ,该模型可以根据一个给定的密码,生成一系列该密码的变体,用于猜测用户可能使用的其它密码。在作者的攻击模型中,作者假设被攻击的用户至少已经泄露了一个密码,所以在这个模型中,可以根据已经泄露的密码来生成一系列的变体密码,用于猜测。
特点与不足
优点:
pass2path 模型可以很方便的部署到网站上,并且兼容网站自身的密码策略(比如,必须要有大写字母、小写字母、数字和特殊字符等)。
首次把密码攻击模型应用于实际环境中(康奈尔大学的账户中),并给出相应的实验结果。
缺点:
对于没有泄露过密码的用户,作者的 pass2path 模型攻击成功的概率很低,因为作者的模型是基于用户已经泄露了至少一个密码的这种情况。
对于安全等级较高的网站(例如银行相关的网站,最多只允许输入3次密码,超过3次输入错误就锁定该账户),该攻击方案基本无效。
作者
作者:Pal, Bijeeta (1); Daniel, Tal (2); Chatterjee, Rahul (1); Ristenpart, Thomas (1)
机构:(1) Cornell Tech; (2) Technion
美国康奈尔大学康奈尔科技校区。
论文出处
[1] Pal B, Daniel T, Chatterjee R, Ristenpart T. Beyond credential stuffing: password similarity models using neural networks. 2019 IEEE Symposium on Security and Privacy (SP). San Francisco, CA, USA: IEEE, 2019: 417–434.
实验及效果
数据处理
作者用来训练的原始数据是 14 亿条泄露的“电子邮件-密码对”,在这当中有 11 亿个唯一的电子邮件,4.63 亿个唯一的密码。这些数据是 2017 年 12 月 5 日之前泄露的数据,数据的来源包括 Linkedin, Myspace, Badoo, Yahoo, Twitter, Zoosk, Neopet 等。
在作者的实验中,这些数据还不能直接使用,还需要对数据进行过滤与处理,主要处理包括:
只要包含 20 个(或超过 20 个)16 进制值的子串的密码,则丢弃,因为这种情况一般是密码的哈希值,不是真正的密码。
只要包含非 ASCII 码字符的密码,则丢弃。
只要密码超过 30 个字符,或者少于 4 个字符,则丢弃。
还有一些特殊情况。
处理之后的数据,只包含了 4.604 亿个唯一的密码(“电子邮件-密码对” 重复的将被删除),这些密码的分布如表 1 所示:
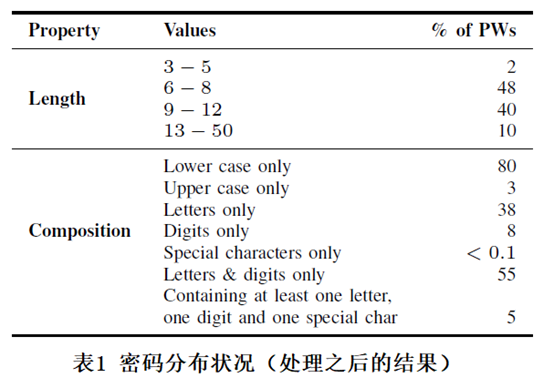
从表 1 中可以看出,密码长度在 6 到 12 之间的,占据总密码 88% 的比例,并且,有 80% 的密码只使用小写字母。另外,作者还发现有 0.9% 的用户直接使用 “123456” 这个简单的密码。
这些数据被过滤之后,还需要做进一步处理,因为作者需要训练的模型就是由一堆生成规则组成,而这些生成规则是由相同用户的不同密码训练而成。目前这些过滤之后的数据还是一条一条的 “电子邮件-密码对”,因此,作者需要知道这些数据里面哪些密码是属于同一个用户的。这就需要合并这些 “电子邮件-密码对”,把属于同一个用户的所有密码合并到一起。合并的规则有三种:
Email based:把电子邮件相同的 “电子邮件-密码对” 合并,形成一个电子邮件对应多个密码的组合,因为作者认为相同电子邮件的账户应该属于同一个用户。
Username based:把电子邮件按 “@” 符号进行分割,前半部分叫做 Username,作者把 Username 相同的 “电子邮件-密码对” 合并,认为 Username 相同的邮件应该属于同一个用户(但是,这会导致错误的把两个不同的用户进行合并)。
Mixed method:先进行 Email based 合并,再进行 Username based 合并,但是在第二步的时候,还要判断 Username 相同的两组密码中是否存在共同的密码,存在有共同的密码才合并,认为它们都属于同一个用户,否则不合并。
进行合并处理后的结果如表 2 所示:
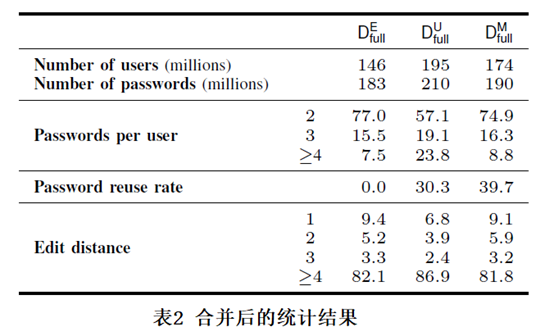
表中最后三列的 “E”、“U”、“M” 分别对应三种合并规则。第二行表示合并后的用户或密码数量,单位是百万个。第三行是统计每个用户所拥有的密码数量,单位是百分比,倒数第四列的 “2” 表示每个用户拥有两个密码的情况,“3” 和 “>=4” 以此类推。第四行表示密码重用率,按照电子邮件进行合并后,密码重用率为 0,是因为之前已经把 “电子邮件-密码对” 相同的条目删除了。最后一行是编辑距离,也就是同一个用户的不同密码之间的转换所需要的的步骤,例如,两个密码:“password”和“passw0rd”的编辑距离为 1。
从表 2 中的第三行可以看出,当使用 “Username based” 策略合并数据的时候,每个用户对应的密码数量分布发生较大的变化,这是由于这种策略错误的把不同用户的密码进行了合并所导致的,因此,后续实验不在使用该组数据。主要实验都在基于 “Email based” 策略合并的结果上做。
作者把 $$ D^{E}{full} $$ 划分为 80% 的训练集 $$ D^{E}{tr} $$ 和 20% 的测试集 $$ D^{E}{ts} $$ 同时,也把 $$ D^{M}{full} $$ 进行了同样的划分,既 80% 的训练集 $$ D^{M}{tr} $$ 和 20% 的测试集 $$ D^{M}{ts} $$ 由于 $$ D^{E}{tr} $$ 和 $$ D^{M}{tr} $$ 的密码数据分布几乎一致,因此,在训练阶段,如果没有特别说明,默认都是用 $$ D^{E}_{tr} $$ 来训练。
密码相似度生成模型(pass2path)
生成模型就是用于生成给定密码的一系列相似的密码(或者叫做该密码的变体),主要工作在于训练阶段,训练输入的数据就是上述划分的训练集,训练的结果就是一个由一系列规则组成的模型,这些规则来源于训练集中的每一个用户的不同密码,例如,某一个用户拥有3个密码,这些规则就是从任意一个密码转换到另一个密码的过程/步骤,也就是相当于编辑距离的计算过程,这些过程包括:
插入一个字符:“ins”
删除一个字符:“del”
替换一个字符:“sub”
从一个密码转换到另一个密码就由这三种操作完成,并且这个转换过程组合起来叫做一次转换:“Transform”。两个密码之间的编辑距离就是一次转换所需要执行的步骤数量。最后训练出来的模型大约 60MB 左右,训练时间大约是 2 天,训练所使用的机器的配置为: Intel Core i9 处理器和 GTX 1080 GPU。
防御策略(vec-ppsm)
虽然目前主流的网站中已经部署了一些密码强度检测的系统(例如,在你输入一个新的密码的时候,一般在密码旁边会显示当前密码的强度),但是,这些检测系统一般比较简单,通常只会检测密码是否有大写字母、小写字母、数字和特殊字符等。而用户在更新密码的时候,很有可能只是使用一个当前密码的一个变体来更新旧密码(例如:把旧密码:“password” 更新为:“pasw0rd”),这种情况在作者的攻击模型中是极易被攻击的。因此,作者提出了一个新的密码强度检测系统: vec-ppsm(Personalized Password Strength Meters),该系统根据已经泄露的密码构建一个模型,用来评估当前密码的强度,所使用的技术是:基于神经网络的单词嵌入技术(Neural Network-based Word Embedding Techniques)。
vec-ppsm 使用 Word Embedding 技术,作者把它命名为 Password Embeeding,既把一个密码映射到一个 d 维的向量空间(文中使用的 d=100),然后使用 FastText 模型 来学习密码之间的相似度,训练好的模型有 50MB 左右。由于该系统一般在用户更新密码、或者注册用户输入新密码的时候使用,一般在客户端使用,通常通过 Java Script 脚本把模型发送到客户端,所以, 50MB 的模型相对过大,需要压缩(作者使用 Product Quantization 技术来压缩模型,该压缩技术由 Facebook 的 Faiss library 提供),压缩就涉及到压缩率和模型的精度之间的衡量问题,如表 3 所示:
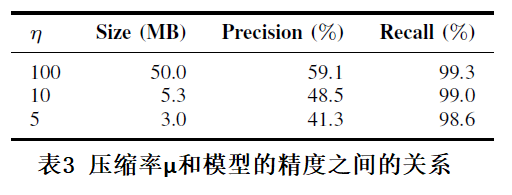
如表 3 所示,表中第一列为压缩率。经过权衡之后,作者认为选择压缩率为 5 的时候比较合适,此时模型大小为 3MB,适合网络传输,精度损失也不大,在可以接受的范围内。
实验及效果
实验环境
CPU:Intel Core i9
内存: Unknown
OS: Unknown
GPU:GTX 1080
数据集:
数据集包括模拟测试使用的两个测试数据集: D^{E}{ts}D^{M}{ts}以及在真实环境中测试使用的数据集:Cornell Accounts。
- 模拟测试
模拟测试使用的是两个测试集进行测试,测试过程中使用到一个参数 q,表示对某个密码的猜测次数,q 有三种选择,分别是:10、100、1000。此外,作者把这两个数据集分别部署到两个服务上去,并设置两个服务的属性, $$ D^{E}{ts} $$ 对应的服务的属性为:“without-repeat”,也就是该服务中的密码不允许重复,而 $$ D^{M}{ts} $$ 对应的服务的属性为:“with-repeat”,也就是该服务中的密码允许重复,实验数据如表 4 所示:
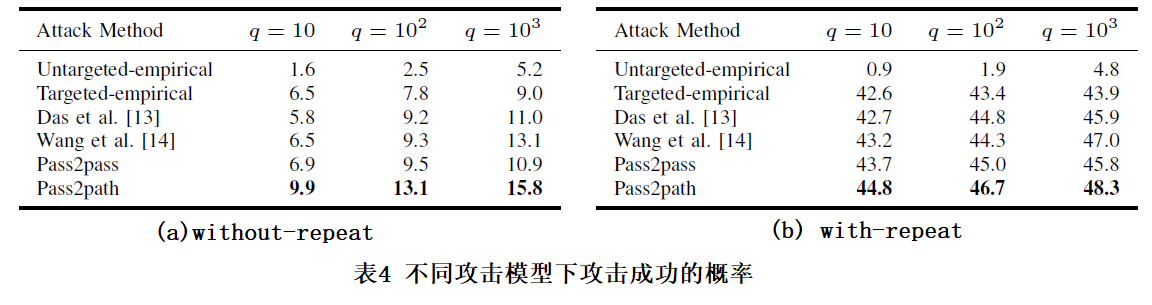
表4 不同攻击模型下攻击成功的概率
从表 4 中可以看出,作者设计的模型 pass2path 在两个数据集中攻击成功的概率都是最大的,即使随着参数 q (一个密码被允许攻击的次数) 的不同,作者的模型所能达到的效果也是最优的。此外,还可以看出右边表格中的百分比相对较大,这是因为右边表格中的数据对应的服务的属性被设置为“with-repeat”,对用户的密码限制比较宽松,允许用户密码重复,这就导致了很多密码是重复的,并且很多密码和训练集中的密码一样,因此,攻击成功的概率大幅增加。而左边表格对应的数据集,在它的服务中是不允许出现重复密码的,因此,攻击成功的概率相对较低。
此外,作者还做了一个实验,就是从 $$ D^{E}_{ts} $$ 数据集中随机选取了 10 万个用户,这些用户都至少泄露了 2 个密码以上,作者选择其中一个密码当做泄露的密码,其它密码当做被攻击的密码,分别使用 pass2path 模型和 Untargeted 模型(Untargeted 模型就是从训练数据集中把用户密码按流行度从高到低排序,生成一个密码列表,攻击目标的时候,从流行度最高的密码开始尝试,然后选流行度次高的密码来尝试,以此类推,直到攻击成功,或者攻击次数达到设定值为止,而不管被攻击的目标是谁)来攻击这些用户的密码,结果如图 2 所示:
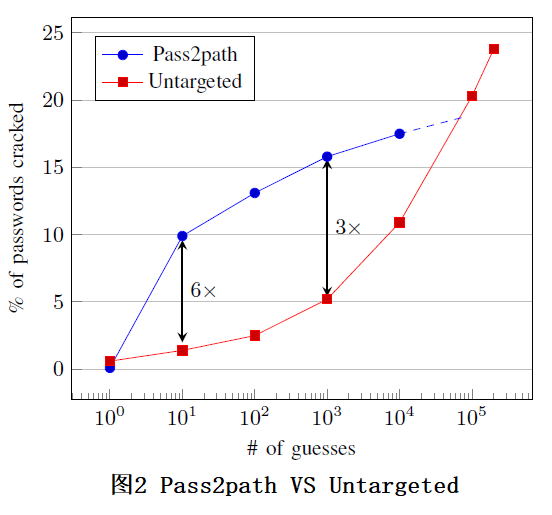
如图 2 所示,作者画了二者的曲线图,由于计算能力有限,当猜测次数 q 大于 1 万的时候,作者不再计算 pass2path 的攻击成功率,而是根据曲线的走势,用虚线描绘了它们的形状。从图中也可看出,当猜测次数较小的时候(小于 1 万次),pass2path 模型攻击成功的概率远大于 Untargeted 模型,但是随着攻击次数的不断增大, Untargeted 模型最终会超过 pass2path 模型。
现实环境测试
作者通过和 Cornell 大学的信息安全办公室(IT Security Office of Cornell University : ITSO)进行合作,对康奈尔大学的用户账户进行在线测试(包括学生、教师、学校员工等),首先,作者就发现康奈尔大学的用户账户中,有 19868 个电子邮件出现在被泄露的用户数据中,也就是说,这些用户至少已经泄露了一个密码。其次,奈尔大学自从 2009 年开始记录用户的密码变更情况,变更过密码的账户有 15776 个,作者对这 15776 个账户进行测试。由于康奈尔大学对用户的密码执行 L8C3 策略,既,用户密码必须包含 8 个(或以上)字符,并且必须包含大写字母、小写字母、数字和特殊字符中的 3 类(或以上)字符。因此,用户密码的安全性相对较高,测试中攻击成功的概率也会略低于测试数据集中的结果,测试结果如图 3 所示:
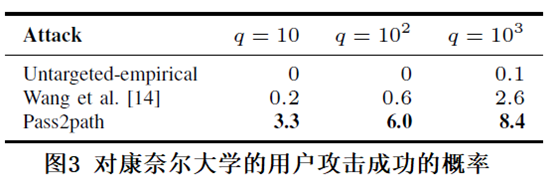
作者使用了三种模型进行攻击,从图中可以看出基于经验的无目标攻击模型(Untargeted-empirical)攻击成功的概率非常低,当猜测次数 q=1000 的时候才有 0.1% 的成功率,而作者的 pass2path 模型攻击成功的概率最高,当 q=1000 的时候,能够攻击成功的概率达到 8.4%。也就是说,康奈尔大学的账户有 1374 个活跃的账户易受远程密码猜测攻击。作者把这些数据提交给 ITSO,并和他们一起保护康奈尔大学的账户信息。
vec-ppsm 测试
为了评估 vec-ppsm,作者选了其它的一些密码强度评估工具进行对比,作者认为,一个密码在 1000 次猜测中无法攻击成功的就被标志为:“Uncracked”。作者从 $$ D^{E}_{ts} $$ 中随机抽取 10 万个用户进行测试,测试结果如图 4 所示:

图4 密码强度评估
图中第一列是密码强度评估工具, vec-ppsm 是作者设计的模型,带 compressed 表示压缩后的模型,图中第二列和第三列表示:在各个工具评估出来的结果中,认为不安全的结果所占的比率,q 表示猜测次数,当这个密码能够被 pass2path 在 q 次猜测之内猜测出来的时候,这个密码被认为是不安全的。表中的第四列表示:当 pass2path 猜测 1000 之后,仍然没有被猜测出来的比率。
收获
总得来说,这篇文章包含两个关键部分:一部分是作者提出的 pass2path 模型,该模型对于一个给定的密码,生成该密码的一系列变体,用于猜测使用过该密码的用户可能使用的其它密码;另一部分是作者提出的防御方案 vec-ppsm,该方案主要针对作者的这种攻击场景,如果用户使用的密码是旧密码的一个变体,或者是某一个已经泄露的密码的一个变体,则这个防御方案会提示用户密码的安全强度低,而不管这个密码有多复杂,因为 pass2path 可以轻易的从已有密码中衍生出该变体。最后,作者把 pass2path 模型应用到真实的环境中(康奈尔大学的账户中),这也是之前的工作都没有做过的。康奈尔大学对账户密码的要求已经算是比较严格的(强制采用 L8C3 策略),但是在作者的这个模型中,在小于 1000 次猜测的情况下,发现他们的账户仍有 8.4% 可以被攻破。最后,相比于之前的工作,作者的攻击模型所取得的效果最优。
这篇文章的切入点就是:用户的密码太多,难于记忆,因此,在不同的网站,用户通常会复用密码,或者只是使用已有密码的一个简单变体,这就使得作者的这个攻击模型比较有效。
可扩展结合的点
这种针对具体问题进行设计方案,通过实验,提出一个实用化工具的论文,挺不错的。
有个非常现实的问题,用户的账号密码通常与用户的个人信息有关,在已经知晓用户个人信息的情况下,如何快速破解密码?
论文评价
评分: ⭐⭐⭐⭐⭐
评价: 分析的非常全面客观。
参考资料及附件
- 上海交通大学GoSSIP笔记: https://loccs.sjtu.edu.cn/gossip/blog/2019/06/21/beyond-credential-stuffing-password-similarity-models-using-neural-networks/
- 作者主页: https://www.cs.cornell.edu/~bijeeta/
- 论文地址: https://www.cs.cornell.edu/~rahul/papers/ppsm.pdf
- 版权声明:本文为 m2kar 的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
- 作者: m2kar
- 打赏链接: 欢迎打赏m2kar
- 邮箱: m2kar.cn#gmail.com
- 主页: m2kar.cn
- Github: github.com/m2kar
- CSDN: M2kar的专栏