论文主题
对中文密码进行实证分析,发现中文密码中有趣的结构和特征,揭示了中文密码的双相安全性(Bifacial-security)。
摘要
英文
Much attention has been paid to passwords chosen by English speaking users, yet only a few studies have examined how non-English speaking users select passwords. In this paper, we perform an extensive, empirical analysis of 73.1 million real-world Chinese web passwords in comparison with 33.2 million English counterparts. We highlight a number of interesting structural and semantic characteristics in Chinese passwords. We further evaluate the security of these passwords by employing two state-of-the-art cracking techniques. In particular, our cracking results reveal the bifacial-security nature of Chinese passwords. They are weaker against online guessing attacks (i.e., when the allowed guess number is small, 1∼104) than English passwords. But out of the remaining Chinese passwords, they are stronger against offline guessing attacks (i.e., when the guess number is large, >105) than their English counterparts. This reconciles two conflicting claims about the strength of Chinese passwords made by Bonneau (IEEE S&P'12) and Li et al. (Usenix Security'14 and IEEE TIFS'16). At 107 guesses, the success rate of our improved PCFG-based attack against the Chinese datasets is 33.2%~49.8%, indicating that our attack can crack 92% to 188% more passwords than the state of the art. We also discuss the implications of our findings for password policies, strength meters and cracking.
中文
对于英语用户所选择的密码已给予了很多关注,但只有少数研究研究了非英语用户如何选择密码。在本文中,我们对7,310万个真实世界的中文Web密码(与3,320万个英语相对应的英文密码)进行了广泛的实证分析。我们重点介绍了中文密码中许多有趣的结构和语义特征。我们通过采用两种最新的破解技术来进一步评估这些密码的安全性。特别是,我们的破解结果揭示了中文密码的双面安全性。与在线密码攻击相比,它们对在线猜测攻击的抵抗力较弱(即,当允许的猜测数字较小时,为1到104)。但是在其余的中文密码中,它们比英文对应的密码更能抵抗离线猜测攻击(即,当猜测数字大于105时)。这与关于Bonneau(IEEE S&P'12)和Li等人的中文密码强度的两个矛盾说法相吻合。 (Usenix Security'14和IEEE TIFS'16)。根据107个猜测,我们改进的基于PCFG的针对中国数据集的攻击的成功率为33.2%〜49.8%,这表明我们的攻击可以破解比现有技术多92%至188%的密码。我们还将讨论我们的发现对密码策略,强度计和破解的影响。
关键字
密码;密码猜解
解决问题
现实问题
文本密码是当今几乎每个Web服务中访问控制的主要形式。尽管早在四十年前就已经揭示了它们的安全隐患,并且自那时以来已提出了各种替代的身份验证方法(例如,图形密码和多因素身份验证),但密码仍被广泛使用。其中一个原因是密码具有许多优点,例如部署成本低,易于恢复和明显的简单性,而其他身份验证方法往往无法提供这些优点。另一个原因则是由于边际收益(marginal gain)通常不足以弥补重大的过渡成本,因此缺乏有效的工具来量化不太明显的替换密码成本。此外,用户也喜欢密码。
之前研究的不足
截至2018年6月,中国有8.02亿网民,占世界互联网人口的20%以上(也是最大比例)。以下关键问题还没有令人满意的答案:
(1)是否存在区分中文密码和英文密码的结构或语义特征?
(2)中文密码如何应对主流攻击?
(3)他们是否比英语弱或强?
这些问题必须解决,以便为安全工程师和中国用户提供必要的安全指导。例如,如果第一个问题的答案是肯定的,则表明密码策略(例如length-8 + 2Class12 RNN-PSMZxcvbn
方法
实证分析
通过首次利用7310万个真实的中文密码:
(1)定量评估用户密码在多大程度上受到其母语的影响;
(2)系统地探索密码中的常见语义(例如日期,名称,地点和电话号码);
(3)表明,尽管这两个用户组的密码是在不同的密码策略下创建的,但它们遵循非常相似的Zipf频率分布。
反转原理(reversal principle)
采用两种最先进的密码破解算法(即基于PCFG和基于Markov的算法])来衡量中文Web密码的强度,本文还改进了基于PCFG的算法,以更准确地捕获具有单调长结构的密码(例如“ 1qa2ws3ed”)。“反转原理”即中文密码的双相安全性:当允许的猜测数字较小时,它们比英语密码弱得多,但是当猜测数字较大时,这种关系就被逆转了。从而调和以往文献中的互相矛盾主张。
中国的密码特点
数据集和道德考虑
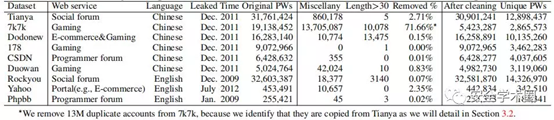
本文的实证分析使用了来自中文网站的六个密码数据集和来自英文网站的三个密码数据集。总共这9个数据集包含1.063亿个实际密码。如下表所示,这9个数据集在服务,语言,文化和规模方面有所不同。他们在2009年至2012年间遭到黑客攻击并在互联网上公开发布。
尽管这些文献是公开可用的并且在文献中得到了广泛使用,但是这些数据集是私人数据。因此仅报告汇总的统计信息,并将每个单独的帐户视为机密信息,以便在研究中使用该帐户不会增加对相应受害者的风险,即,无法学习到任何可识别个人身份的信息。此外,这些数据集可能被攻击者用作破解字典,而本文的使用既有益于学术界了解中国网民的密码选择,也有益于安全管理员保护用户帐户。由于数据集都是公开可用的,因此这项工作的结果是可重复的。
数据清理
本文注意到一些原始数据集(例如Rockyou和Tianya)包含不必要的标题,说明,脚注,len> 100的密码字符串等。因此,在进行任何探索之前,首先启动数据清理。将从原始数据中删除电子邮件地址和用户名。进一步删除len> 30的字符串,因为在手动检查原始数据集之后,发现这些长字符串似乎不是由用户生成的,而是由密码管理器或仅是垃圾信息生成的。而且,如此长的密码通常超出了关心破解效率的攻击者的范围。总体而言,排除的密码的比例可以忽略不计(请参阅上表中的最后一列),但是此清理步骤统一了破解算法的输入并简化了以后的数据处理。
本文发现Tianya或7k7k已被污染:Tianya数据集和7k7k数据集之间存在不可忽略的重叠(即7k7k的40.85%和天涯的24.62%)。更具体地说首先感到困惑的是,密码“ 111222tianya”最初在两个数据集的前十大最常用列表中。通过手动检查原始数据集(在删除电子邮件地址和用户名之前),惊讶地发现大约有391万的两个数据集中的联合账户。有人将这些联名账户从Tianya复制到了7k7k,但没有像以前的主要研究中得出的那样从7k7k复制到了Tianya。
密码特性
(1)语言依赖性
有一种说法即用户生成的密码受其本国语言的影响很大,但是迄今为止尚未进行大规模的定量测量。为了填补这一空白首先说明了这9个数据集的字符分布,然后根据字符分布的反转数(降序排列)来测量密码与本机语言的接近程度。
不出所料,来自不同语言组的密码具有明显不同的字母分布(请参见下图)。出乎意料的是,即使在多种多样的Web服务中生成和使用了相同语言组的密码,其字母分布也非常相似。这表明,当给定密码数据集时,可以通过调查其字母分布来大致确定其用户的母语。所有中文密码的字母分布按降序排列,是aineohglwuyszxqcdjmbtfrkpv,而所有英文密码的分布是aeionrlstmcdyhubkgpjvfwzxq。虽然两个字母中的某些字母(例如,“ a”,“ e”和“ i”)频繁出现,但是某些字母(例如,“ q”和“ r”)仅在一组中频繁出现。攻击者可以利用这些信息来减少搜索空间并优化其破解策略。请注意,此处所有百分比均不区分大小写。
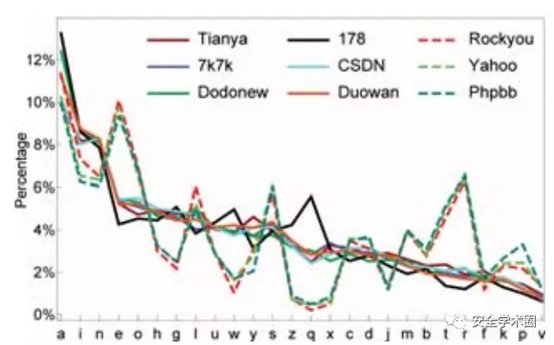
尽管用户的密码会受到其母语的极大影响,但通用语言的字母频率可能与密码的字母频率有所不同。它们在多大程度上有所不同?根据之前的著作将中文(例如文学作品,报纸和学术论文等书面中文文本)转换成中文拼音后的字母分布为inauhegoyszdjmxwqbctlpfrkv。这表明在中文密码中很流行的某些字母(例如“ l”和“ w”)在中文书面文字中的出现频率要低得多。可能的原因可能是,“ l”和“ w”分别是姓氏li和wang(这是中国排名前2位的姓氏)的第一个字母,而正如显示的,中国用户喜欢使用名称创建其密码。
英语用户的密码也有类似的观察结果。英文语言的字母分布(即etaoinshrdlcumwfgypbvkjxqz)来自www.cryptograms.org/letter-frequencies.php。[1] 例如,“ t”在英语文本中很常见,但在英语密码中并不常见。一个合理的原因可能是,“ t”用在了诸如the, it, this, that, at, to之类的流行词中,而这种词在密码中很少见。
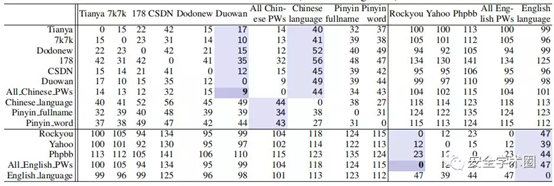
为了进一步探索密码与本土语言和其他数据集的密码的紧密度,测量了两个密码数据集(以及语言)之间字母分布序列的反转数(降序排列)。结果总结在下表中。“Pinyin_fullname”是由2,426,841个独特的中文全名组成的词典(例如wanglei和zhangwei),“Pinyin_word”是由127,878个独特的中文单词(如chang和cheng)组成的词典。请注意,序列A到序列B的反转数等于B到A的反转数。例如,inauh到aniuh的反转数为3,等于aniuh到inauh的反转数。
如下表所示,来自同一语言组的密码之间的字母分布反转数通常比来自不同语言组的密码的反转数小得多。此值也明显小于密码及其本国语言之间的字母分布的值(请参阅表2中的粗体值)。后者的期望值较低。所有这些表明,来自不同语言的密码在字母分布上本质上彼此不同,并且密码接近其本国语言,但区别仍然很大(可测量)。
(2)长度分布
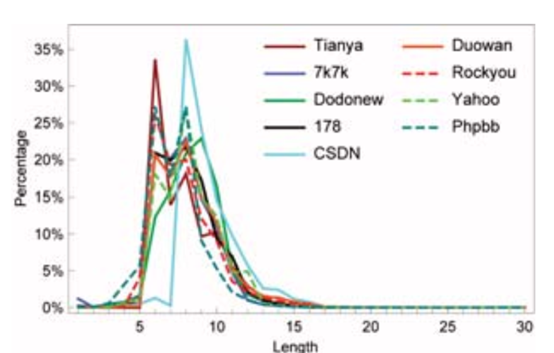
下图描述了密码的长度分布。不论Web服务,语言和文化差异如何,每个数据集的最常用密码长度在6到10之间,其中6到8为首。仅长度为6到10的密码就可以占每个数据集的75%以上,如果考虑长度为5到12位的密码,则该值将升至90%。很少有用户喜欢长度超过15个字符的密码。值得注意的是,人们似乎更喜欢偶数长度而不是奇数长度。另一个有趣的发现是,CSDN在其长度分布曲线中仅显示一个峰值,并且密码的长度<8少得多(即仅2.16%)。这可能是由于密码策略要求此站点上的长度不能小于8。
(3)最受欢迎的密码
下表显示了来自不同服务的前10个最常见的密码。所有数据集中最常见的密码是“ 123456”,CSDN是唯一的例外,因为其密码策略要求密码的长度为8+(见图2)。“111111”紧跟其后。其他流行的中文密码包括“ 123123”,“ 123321”和“ 123456789”,它们均由数字组成,并以简单的方式(例如重复和回文)组成。爱情还展示了其神奇的力量:“ 5201314”,在中文中具有类似的“我永远爱你”的发音,2出现在四个中文数据集的前十名中。相反,英语数据集中的流行字母往往是有意义的字母字符串(例如“ sunshine”和“ letmein”)。永恒的爱情主题-坦率地说,“ iloveyou”,或者也许是委婉地说,是“princess”,也出现在英语数据集的前10名列表中。结果证实了说法“早在网络出现之初,最流行的密码是12345。今天,它虽然长了一位,但更不安全:123456。”
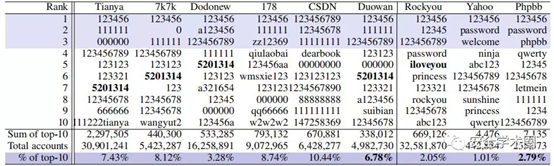
(4)密码中的语义
下表显示了密码中各种语义模式的普遍性。许多说英语的用户倾向于使用原始的英语单词作为其密码构建块:25.88%,将5个字母以上的单词插入其密码。使用5个字母以上的单词的密码占使用5个字母以上的子字符串的密码总数的三分之一以上。相比之下,选择中文单词构建密码的中国用户较少(2.41%),但他们更喜欢拼音名称(11.50%),尤其是全名。
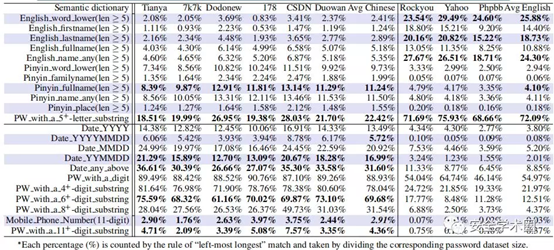
特别是在所有包含5个字母以上的子字符串的中文密码中(22.42%),一半以上(11.24%)包含5个字母以上的拼音全名。也有4.10%的英文密码包含5个字母以上的全拼音名称。一个合理的解释是,许多中国用户已经在这些英语站点中创建了帐户。例如,流行的中文拼音名称“ zhangwei”出现在Rockyou和Yahoo中。还注意到英语名称也广泛用于英语密码中,但是全名不如姓氏和名字流行。
平均有16.99%的中国用户在密码中插入一个六位数的日期。进一步考虑到用户喜欢将自己的信息包含在密码中,这样的日期很可能是用户的生日。此外,约有30.89%的中文用户使用4位数字以上的日期来创建密码,这比英语用户高出3.59倍(即8.61%)。另外,有13.49%的中国用户在密码中输入四位数的年份,这比说英语的用户(3.80%)高3.55倍。注意到可能有一些高估,因为没有办法明确区分某些数字序列是否为日期,例如010101和520520。这两个序列可能是日期,但它们也可能具有其他语义含义(例如520520听起来像“我爱你,我爱你”)。如稍后所述已经设计出解决此问题的合理方法。总之,日期在中国用户的密码中起着至关重要的作用。
主要注意密码长度4、6和8位数字,因为:
1)长度4和6是西方和亚洲使用最广泛的PIN码的长度;
2)6和8是两个最常见的密码长度。
有趣的是,有2.91%的中国用户很可能使用其11位数字的手机号码作为密码,占所有密码的39.59%,其子字符串超过11位。平均而言,中文密码的12.39%长于11。因此,如果攻击者可以确定(例如,通过肩窥)受害者使用了长密码,则她成功的可能性很高,为23.48%(= 2.91%/12.39%),只需尝试受害者的11位数手机号码即可。这揭示了针对长中文密码的实用攻击策略。
请注意,在确定文本/数字序列是否属于特定词典时存在一些不可避免的歧义,而这些歧义的不正确解析会导致过高或过低的估计。这里以“ YYMMDD”为例。例如,111111和520521都属于“ YYMMDD”,并且非常受欢迎。但是,用户选择它们的可能性很可能仅是因为它们是易于记忆的重复数字或有意义的字符串,并将它们视为日期会导致高估。然而,它们确实可以是日期(例如,111111代表“ 2011年11月11日”,而520131代表“ 1952年1月31日”),并且将它们完全排除在“ YYMMDD”之外会导致日期被低估。
因此,假设用户生日是随机分布的,并且将这些日期的期望值(由E表示)而不是零分配给这些异常日期的出现频率。在字典“ YYMMDD”中手动识别出17个异常日期,这些日期最初的频率大于10E,并出现在六个中文数据集的每个前1000个列表中。这样,可以很大程度上解决歧义。同样处理“ MMDD”中的16个异常项。
中文Web密码的强度
现在,使用两种最先进的密码攻击算法(即基于PCFG和基于Markov)来评估中文Web密码的强度, 实际上可以利用例如日期和拼音名称来进行密码猜测
1、基于PCFG的攻击
基于PCFG的模型是最新的破解模型之一。首先,它将训练集中的所有密码划分为相似字符序列的段,并获得相应的基本结构及其相关的出现概率。例如,将“ wanglei @ 123”划分为L段“ wanglei”,S段“ @”和D段“ 123”,从而得到基础结构L7S1D3。L7S1D3的概率是(#of L7S1D3)/(#of base structures)。此类信息用于生成概率上下文无关文法。
然后,人们可以以概率递减的顺序得出密码猜测。每个猜测的概率是其推导过程中所使用的结果的概率的乘积。例如,将“ liwei@123”的概率计算为P(“ liwei@123”)= P(L5S1D3)·P(L5→liwei)·P(S1→@)·P(D3→123)。D和S段的概率是通过计算从训练集中学习的,而L段则是通过从训练集中学习或使用外部输入词典来处理的。本文通过直接从训练集中学习来实例化密码猜测的PCFG L段。
按语言将9个数据集分为两组。对于中文测试集,从Duowan数据集中随机选择1M密码作为训练集(用“ Duowan_1M”表示)。原因是:在数据集“All Chinese PWs”中,Duowan的反转数最少,并且可能最好地表示通用的中文Web密码。同样,对于英语测试集,从Rockyou中选择1M密码作为训练集。由于仅使用了Duowan和Rockyou的一部分,因此将其余的密码和其他7个数据集用作测试集。下图(a)和(b)分别显示了对中文组和英文组的攻击结果。
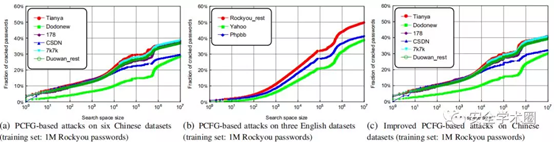
**双相安全。**当允许的猜测数字(即搜索空间大小)小于约3,000时,中文密码通常比同一服务的英文密码弱(例如,Tianya与Rock you,Dodonew与Yahoo和CSDN与Phpbb)。例如,按100个猜测,对Tianya,Dodonew和CSDN的成功率分别为10.2%,4.3%和9.7%,而英语水平分别为4.6%,1.9%和3.7%。但是,当搜索空间大小大于10,000时,中文Web密码通常比英文密码强得多。例如,在1000万个猜测中,对Tianya,Dodonew和CSDN的成功率分别为37.5%,28.8%和29.9%,而英语水平分别为49.7%,39.0%和41.4%。当猜测数进一步增加时,强度差距将更大。这揭示了一种逆转原理,即中文密码的双相安全性:与英文密码相比,它们更容易受到在线猜测攻击(即,当允许的猜测数较小时);但是,在剩下的中文密码中,它们更安全地防止了离线猜测。这种双面安全性很大程度上是由于基于数字的密码的双面密度性质:基于最高数字的密码更加趋同,而数字通常比字母更具随机性(且发散性)。
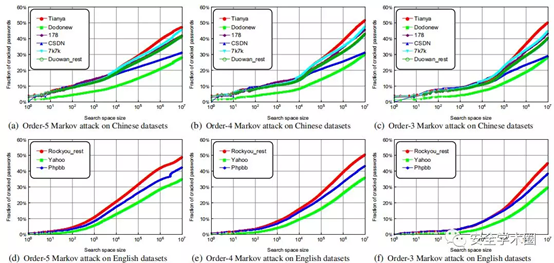
2、基于马尔可夫的攻击
为了显示了关于口令安全性的结果的鲁棒性,还对基于马尔可夫的攻击进行了进一步的研究。
为了使实验尽可能重现,现在进行详细设置。考虑了两种平滑技术(即Laplace平滑和Good-Turing平滑)来处理数据稀疏性问题,以及两种归一化技术(即基于分布和基于结束符号的方法)来处理密码长度分布不平衡问题。这在下表中带来了四种攻击情形。在每种情形下,考虑三种类型的马尔可夫阶(即5阶,4阶和3阶)来研究哪种顺序表现最佳。
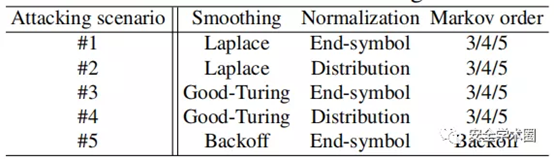
五个场景的实验结果非常相似。这里主要显示下图中方案1的攻击结果,而方案2和5的实验结果由于空间限制而被省略。
可以看到,对于中文和英文测试集:(1)在较大的猜测(即> 2 * 106)下,四阶马尔可夫链显然比其他两个阶更好,而在较小的猜测下( 即<106)阶数越大,性能将越好;(2)在较小的猜测下,Laplace和GT Smoothing在性能上几乎没有差异,而随着猜测数的增加,Laplace Smoothing的优势变得更大;(3)结束符归一化总是比基于分布的方法更好,而小的猜测它的优势将更加明显。以前的主要研究尚未报道过这种观察。这表明:1)大体上以4阶,拉普拉斯平滑和末端符号归一化(见图6(b)和6(e))进行的攻击效果最佳;和2)稍作猜测,偏爱5阶,拉普拉斯平滑和末端符号归一化的攻击(见图6(a)和6(d))表现最佳。
结果表明,PCFG攻击中发现的双相安全性也适用于所有马尔可夫攻击。例如,在基于4阶马尔可夫链的实验中(参见下图(b)和(e))当猜测数字低于7000左右时,中文Web密码通常很多 比他们的英语弱。例如,按1000个猜测,对Tianya,Dodonew和CSDN的成功率分别为11.8%,6.3%和11.6%,而英语同行(即Rockyou,Yahoo和Phpbb)分别仅为8.1%,4.3%和7.1。%。但是当允许的猜测数字超过104时,中文Web密码通常比英文密码强。例如,根据106个猜测,对Tianya,Dodonew和CSDN的成功率分别为38.2%,20.4%和25.4%,而他们的英语水平分别为38.6%,24.8%和32.3%。
影响
“双相安全性”的发现表明,中国密码更容易受到在线猜测攻击。这是因为最受欢迎的中文密码比较集中。因此一个特殊的黑名单包括一个中等数量的最常见的中文密码(例如10K到20K),对于中文站点抵御在线猜测非常有帮助。可以从各种泄漏的中国数据集中获知这样的黑名单(http://t.cn/RG88tvF)。落入该列表的任何密码将被视为弱密码。但是,众所周知,如果某些流行密码(例如woaini1314)被禁止,则会出现新的流行密码(例如w0aini1314)。这些新的流行密码可能不在静态黑名单中,并且难以检测。因此仅密码创建策略(例如,长度和黑名单规则)就足以防止这种弱密码。需要一种深度防御方法:只要有可能,除了密码创建策略外,安全性至关重要的服务还可以进一步使用密码强度表(例如,fuzzyPSM和Zxcvbn)来检测和防止弱密码。
特点与不足
这篇文章是一篇分析类型的文章,没提出新的方法,但是分析的角度很全面。
可扩展结合的点
这种安全性评测的文章也可以考虑。
论文评价
评分: ⭐⭐⭐⭐⭐
评价: 分析的很全面。有很大价值。
作者
作者是来自北京大学的Ding Wang和Ping Wang。另外还有武汉大学的Debiao He以及来自弗吉尼亚大学的Yuan Tian。
汪定是来自北京大学电子工程与计算机科学学院的博士后。
主页:http://wangdingg.weebly.com/
做了很多密码强度验证、密码破解、认证相关的工作,成果发在USENIX,CCS,NDSS上,成果满满。
论文出处
[1] Wang D, Wang P, He D, Tian Y. Birthday, name and bifacial-security: understanding passwords of chinese web users. 28th USENIX Security Symposium (USENIX Security 19). Santa Clara, CA: USENIX Association, 2019: 1537–1555.
参考资料及附件
本笔记转载自 https://mp.weixin.qq.com/s/Xywl2gJbonvosW-Gm10MjQ ,侵删
- 版权声明:本文为 m2kar 的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
- 作者: m2kar
- 打赏链接: 欢迎打赏m2kar
- 邮箱: m2kar.cn#gmail.com
- 主页: m2kar.cn
- Github: github.com/m2kar
- CSDN: M2kar的专栏